POSTED ON 25 AUG 2020
READING TIME: 7 MINUTES
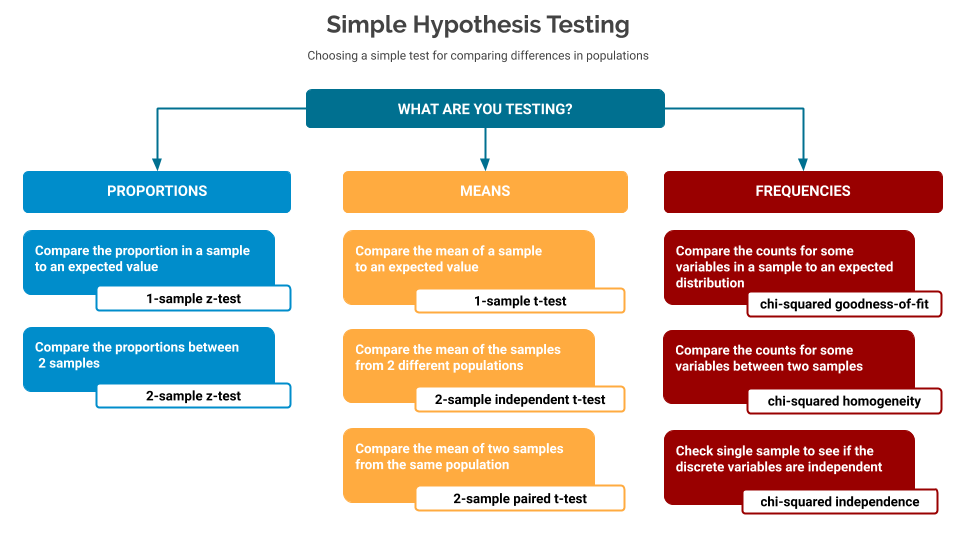
Hypothesis testing of frequency-based samples


Part 4 of our Introduction to Hypothesis Testing series.
In part one of this series, we introduced the idea of hypothesis testing, along with a full description of the different elements that go into using these tools. It ended with a cheat-sheet to help you choose which test to use based on the kind of data you’re testing.
Part two outlined some code samples for how to perform z-tests on proportion-based samples.
Part three outlined some code samples for how to perform t-tests on mean-based samples.
This post will now go into more detail for frequency-based samples.
If any of these terms - Null Hypothesis, Alternative Hypothesis, p-value - are new to you, then I’d suggest reviewing the first part of this series before carrying on with this one..
What is a frequency-based sample?
In these cases we’re interested in checking frequencies, e.g. I’m expecting my result set to have a given distribution: does it?
Are differences between the distributions of two samples big enough that we should notice it? Are the distributions between variables in a single sample enough to indicate that the variables might depend on each other?
Requirements for the quality of the sample
For these tests the following sampling rules are required:
| Random | The sample must be a random sample from the entire population |
| Normal | The sample must be normal, for these tests either:
|
| Independent | The sample must be independent - for these tests a good rule of thumb is that the sample size be less than 10% of the total population. |
Tests for mean-based samples
All of these code samples are available in this git repository
Chi-squared quality-of-fit
Compare the counts for some variables in a sample to an expected distribution
In this test we have an expected distribution of data across a category, and we want to check if the sample matches that.
For example, suppose a network was sized to have the expected distribution, and a sample observed the following counts
| Class of Service | Expected Distribution | Observed Count in sample (size 650) |
| A | 5% | 27 |
| B | 10% | 73 |
| C | 15% | 82 |
| D | 70% | 468 |
Given a null hypothesis that the distribution is as expected, then the following python code would derive the probability that the sample fits into this expected distribution.
from scipy.stats import chisquare
# can we assume anything from our sample
significance = 0.05
# what do we expect to see in proportions?
expected\_proportions = \[.05, .1, .15, .7\]
# what counts did we see in our sample?
observed\_counts = \[27, 73, 82, 468\]
########################
# how big was our sample
sample\_size = sum(observed\_counts)
# we derive our comparison counts here for our expected proportions, based on the sample size
expected\_counts = \[float(sample\_size) \* x for x in expected\_proportions\]
# Get the stat data
(chi\_stat, p\_value) = chisquare(observed\_counts, expected\_counts)
# report
print('chi\_stat: %0.5f, p\_value: %0.5f' % (chi\_stat, p\_value))
if p\_value > significance:
print("Fail to reject the null hypothesis - we have nothing else to say")
else:
print("Reject the null hypothesis - suggest the alternative hypothesis is true")Chi-squared (homogeneity)
Compare the counts for some variables between two samples
In this case, the test is similar to the best fit (above) but rather than estimate the expected counts from the expected distribution, the test is comparing two sets of sampled counts to see if their frequencies are different enough to suggest that the underlying populations have different distributions.
This is, in effect, the same code as above - only in this case we have actual expected values to match, rather than having to estimate them from the sample.
from scipy.stats import chisquare
# can we assume anything from our sample
significance = 0.05
# what counts did we see in our samples?
observed\_counts\_A = \[32, 65, 97, 450\]
observed\_counts\_B = \[27, 73, 82, 468\]
########################
# Get the stat data
(chi\_stat, p\_value) = chisquare(observed\_counts\_A, observed\_counts\_B)
# report
print('chi\_stat: %0.5f, p\_value: %0.5f' % (chi\_stat, p\_value))
if p\_value > significance:
print("Fail to reject the null hypothesis - we have nothing else to say")
else:
print("Reject the null hypothesis - suggest the alternative hypothesis is true")Chi-squared (independence)
Check single sample to see if the discrete variables are independent
In this case you have a sample from a population, over two discrete variables, and you want to tell if these two discrete variables have some kind of relationship - or if they are independent.
NOTE: this is for discrete variables (i.e. categories). If you wanted to check if numeric variables are independent you’d want to consider using something like a linear regression.
Suppose we had a pivot to see how people from different area types (town/country) voted for three different political parties.
The question we are asking is whether or not we can say whether or not there is likely to be a connection between these two variables (i.e. do town/country people have a strong preference to vote for a given party).
| Party | |||
| Cocktail Party | Garden Party | Mouse Party | |
| Voter Type | |||
| Town | 200 | 150 | 50 |
| Country | 250 | 300 | 50 |
The python code to check this is:
from scipy.stats import chi2\_contingency
import numpy as np
# can we assume anything from our sample
significance = 0.05
pivot = np.array(\[
# town votes
\[200,150,50\],
# country votes
\[250,300,50\]
\])
########################
# Get the stat data
(chi\_stat, p\_value, degrees\_of\_freedom, expected) = chi2\_contingency(pivot)
# report
print('chi\_stat: %0.5f, p\_value: %0.5f' % (chi\_stat, p\_value))
if p\_value > significance:
print("Fail to reject the null hypothesis - we have nothing else to say")
else:
print("Reject the null hypothesis - suggest the alternative hypothesis is true")Where do we go next?
Thank you for reading the final part of our introduction into hypothesis testing. I hope you found it a useful introduction into the world of statistical analysis. If you would like to look deeper into this field, I’d suggest the following.
- I’ve not touched on issues of power or effect size in this series. For that I would direct you to Robert Coe’s always worth reading: It's the effect size, stupid: what effect size is and why it is important
- If you have more complex types of data to examine, then I’d suggest reading more into
- Analysis Of Variance - for when you have means in more than two sets of groups to compare, and using multiple t-sets would waste your power.
- Linear Regression - for when you want to predict the value of one continuous variable, based on the values of some other continuous value, or just want to see if different continuous variables are, in fact, related.
- If our previous post - Quantitative analysis is as subjective as qualitative analysis - is making you doubt whether you can trust stats at all, then check out how meta analysis can be used to collect the results of multiple different analyses, and produce a single overall measure as to whether the underlying tests show a significant interaction.
If you would like to know more or have any suggestions, please don't hesitate to reach out to us!