POSTED ON 13 FEB 2020
READING TIME: 6 MINUTES
Multi-Tenant applications with JHipster


Modern web applications are complex; there are a multitude of ways of building them and a seemingly endless set of technology choices. Starting a project with an empty directory can be daunting and it can take a lot of effort to get beyond a canonical “Hello, World!” app. JHipster, a popular application generator, best-of-breed technology choices with industry best practice design to allow developers get on with developing their application logic and user interface without getting tied up in the plumbing unless they really want to.
We’ve certainly found JHipster to be very useful for certain types of projects but found that we needed to add multi-tenancy support to the JHipster applications on more than one occasion. Unfortunately, JHipster doesn’t provide multi-tenancy support as an option but it has an extension mechanism allowing developers to create Blueprints that extend JHipster functionality.
With that in mind, and given that multi-tenancy is quite a common requirement for us, we took the opportunity to learn more about JHipster Blueprints and developed our own for creating multi-tenant applications.
Introducing the JHipster Multi-tenancy Blueprint
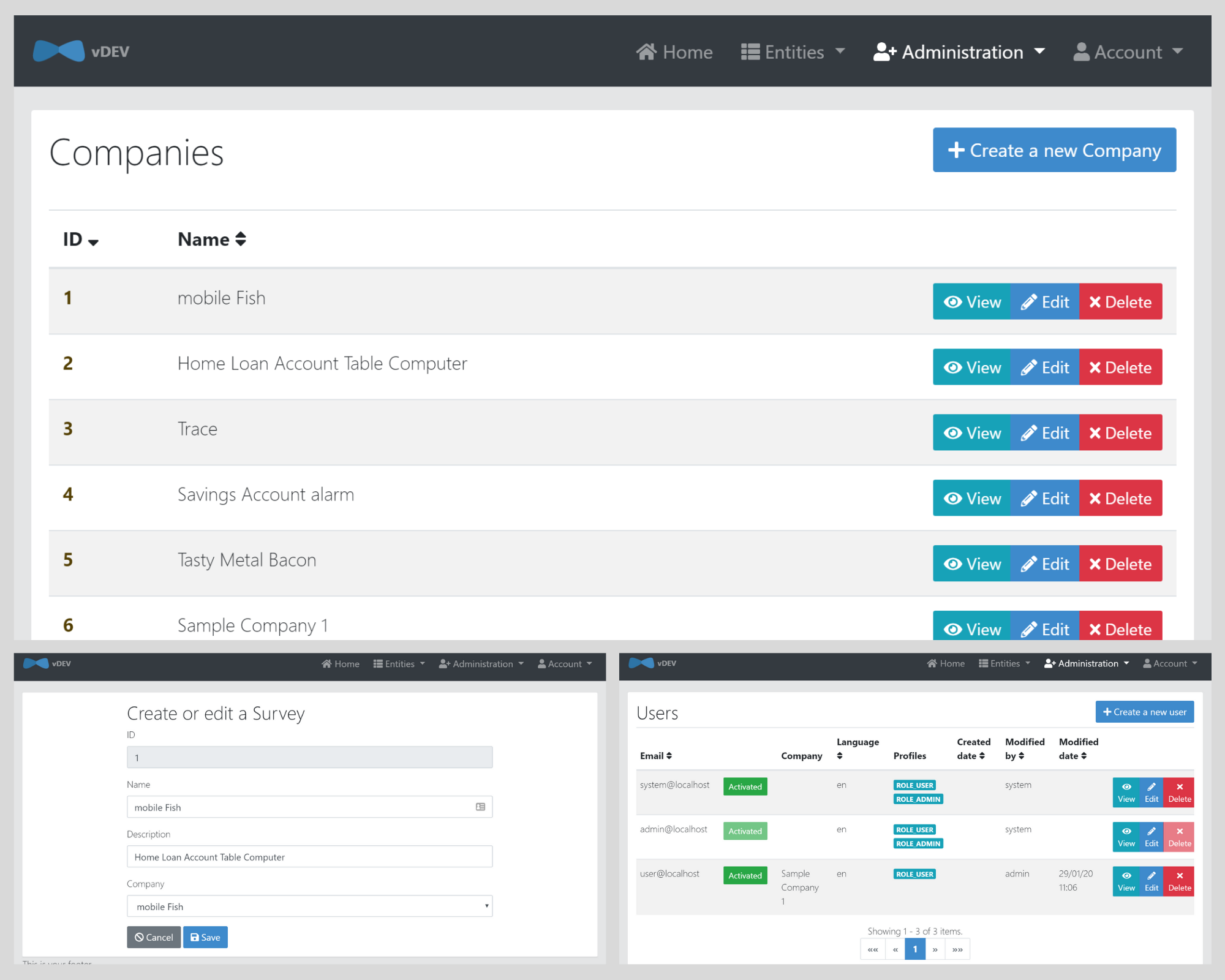
Our Blueprint structures your JHipster application to support multi-tenancy. Once you run it, your generated JHipster application will have the ability to provision and manage tenants and users, with all tenant aware data automatically separated. The Blueprint is very easy to implement and extend, providing the core values of multi-tenancy, to a known coding standard.
Out of the box, you will get the following:
- A suite of tenant management screens available to admins
- User management screens that allow the administrator to assign users to a tenant
- The ability to make any entity tenant aware. A tenant aware entity is then automatically filtered by the logged-in user’s tenant
Under The Hood
There are three common approaches to multi-tenancy:
- Separate databases
- Separate schemas
- Partition the data on a single database schema
After some investigation, we found the most suitable option was to implement a custom discriminator using Spring, Hibernate, and AspectJ. Here is a breakdown of the key operations that the Blueprint performs to provide multi-tenant functionality to your JHipster application.
- Automatically creates a tenant entity. The name of that entity is provided by the user when running the Blueprint. The examples below use “Company” as the tenant entity.
@Entity
@Table(name = "company")
@Cache(usage = CacheConcurrencyStrategy.NONSTRICT\_READ\_WRITE)
public class Company implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
…..
}- Extends the user object with a many-to-one relationship to the tenant along with the filter definition
@Entity
@Table(name = "jhi\_user")
@FilterDef(name = "COMPANY\_FILTER", parameters = {@ParamDef(name = "companyId", type = "long")})
@Filter(name = "COMPANY\_FILTER", condition = "company\_id = :companyId")
public class User extends AbstractAuditingEntity implements Serializable {
…..
@ManyToOne
private Company company;
…..
}- Provides Angular or React views, routes, and services for tenant and user management
- Extends user management views to allow a user to be assigned to a tenant
- Implements data partitioning using AOP to enable Hibernate filters for any tenant aware entity, for example “User”
@Before("execution(\* com.mycompany.myapp.service.UserService.\*(..))")
public void beforeExecution() throws Throwable {
….
User user = userRepository.findOneByLogin(login.get()).get();
if (user.getCompany() != null) {
Filter filter = entityManager.unwrap(Session.class).enableFilter("COMPANY\_FILTER");
filter.setParameter(fieldName, user.getCompany().getId());
}
}Getting Started
To use the Blueprint, follow these steps.
- Install the Blueprint
$ npm install -g generator-jhipster-multitenancy
- Generate your JHipster Multi-tenant application, running the below command in an empty directory
$ jhipster --blueprints multitenancy
- Along with all the existing JHipster questions, you will be asked to provide an alias for tenants.
What is the alias given to tenants in your application?
- Once the Blueprint has generated your application it will contain a tenant entity. All entities you create from here on out can be made tenant aware. Create a new entity using the standard JHipster command.
$ jhipster entity Survey
- Upon generation, you will then be asked if you want to make your entity tenant aware.
Do you want to make Survey tenant aware? (Y/n)
The Challenges
Development of this JHipster Blueprint presented some challenges. Broadly, these can be categorised as:
App Configurations
One of the great benefits of JHipster is that it provides a wide range of options when generating your application. Providing support for every combination of the configuration options can make things tricky when developing a Blueprint. For example, entities can have no pagination, pagination, or pagination with infinite scrolling which complicates how a Blueprint can safely modify the default JHipster frontend templates.
Version Compatibility
JHipster development is moving at a rapid pace. With new versions released every couple of weeks maintaining Blueprint compatibility continues to be a challenge. To address this our strategy is to minimise the number of JHipster files that are modified by the Blueprint. This lessens the chances that new or changed JHipster code will be overwritten by the Blueprint.
Partial Updates
Partial updates of generated JHipster files, both frontend and backend, can be done during the writing phase of JHipster Blueprints. This process is achieved by detecting a specific piece of code in a file using regular expressions, and inserting custom code either instead of, or alongside regex matches. Establishing the correct regex pattern to use to detect the targeted code can be a time consuming process and frustrating. This is mainly due to the different stages of formatting that JHipster carries out during the code generation process.
Best Practices
The JHipster development team follows certain coding policies to ensure best practices on all the code they deliver. We value this and make every effort to ensure that the multi-tenant Blueprint adheres to the high standards of the JHipster team. A big challenge throughout Blueprint development is ensuring that the generated code remained true to this objective.
Contributors Needed
All this takes work and often we struggle to make the time to keep up to date with the pace of JHipster development. If you’re a Java, Angular, React, or Vue.js developer and you’d like to help, please get in touch!
Check out the code for the Blueprint on GitHub, or if you just want to see what the Blueprint gives you, check out our sample Angular and React apps.