POSTED ON 20 JAN 2022
READING TIME: 10 MINUTES
Integration testing done right


Writing integration tests is not always straightforward. By definition, integration tests require interaction between several components, and we need to deal with them in many different ways. Let’s look at some tools that will make writing and reading tests easier. I believe that Testcontainers and the Spark framework will allow you to write shorter and more descriptive tests.
Is this how you test?
What is your approach to writing an integration test (IT)? Maybe some of the following sound familiar:
- Write mocks or stubs of external services
- Create a dedicated remote environment for ITs (playground, sandbox) and run them there
- Setup all the components (where the ITs are supposed to run) locally
No, I’m not saying that you’ve been doing it all wrong if you do that! But the truth is each of those approaches has drawbacks. By way of example, let’s look at the first option.
When you mock or stub some external services that are not crucial for the component you are testing, there is a chance you might miss some aspects of that mocked service that can only occur when running live.
Of course, you could invest more effort into replicating the logic of how the actual component works, but it might be difficult to replicate accurately and will also be time-consuming to develop. Even then, there are no guarantees it will be correct, so your test might still be unreliable.
What if there was a more effective way? Let’s see what we can do to make real integration tests and not imitation ones!
Meet Testcontainers
Testcontainers is a Java library that supports JUnit tests providing lightweight instances of anything that we can run in a Docker container.
I will go through a use case where Testcontainers can provide substantial benefits.
In the project I’m currently working on, we have a component called the Integration Component (IC). IC is a Spring Boot service that acts as a consumer and a producer of RabbitMQ messages. As a consumer, it listens to a queue where another service sends job requests. IC reads those messages (job requests), processes them and finally sends an HTTP request to Databricks to run a job. Before we submit the request (step #4 on the diagram below), we need to do a few other things, and we have divided this logic into several steps in the IC.
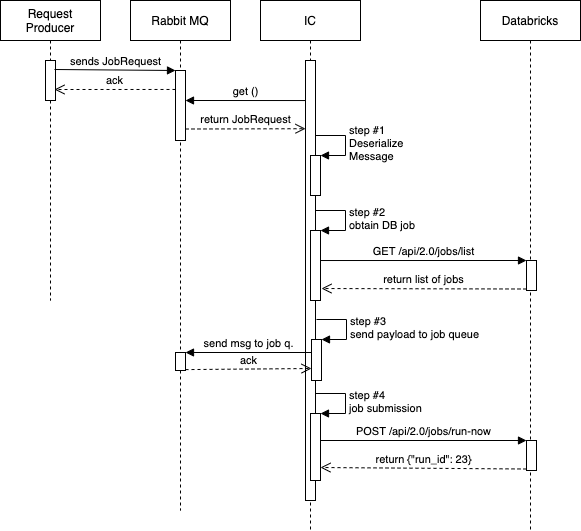
For testing purposes, those requests are handled by the Spark framework, but I'll get back to that later.
As mentioned before, the service logic is divided into several steps, where each step has a process() method. Let’s look at the SendRequestToJobQueueStep method (#3 on the diagram above).
@Slf4j
@RequiredArgsConstructor
@Component
public class SendRequestToJobQueueStep implements JobRequestConsumerStep {
private final AmqpAdmin amqpAdmin;
private final Exchange exchange;
private final RequestQueueProvider requestQueueProvider;
private final RabbitTemplate rabbitTemplate;
@Value("${config.request-queue-ttl}")
private Duration requestQueueTtl;
@Override
public boolean process(JobRequestProcessingContext context) {
String queueName = createAndBindRequestQueue(runSettings.getTraceId(), context.getJobType());
try {
Supplier<? extends SpecificRecordBase> requestProvider = context.getRequestProvider();
sendJobRequestToRequestQueue(requestProvider.get(), queueName);
} catch (AmqpException e) {
String customMsg = String.format("Sending '%s' request using routing key '%s' for jobId=%d failed.", context.getJobType(), queueName, job.getJobId());
log.error(prepareExceptionLogMessage(deliveryTag, e, customMsg), e);
requeue(context, deliveryTag);
return false;
}
return true;
}
private <R extends SpecificRecordBase> void sendJobRequestToRequestQueue(R requestObject, String routingKey) {
rabbitTemplate.convertAndSend(Amqp.EVENTS, routingKey, requestObject);
log.info("Job request is sent to job queue. Routing key: '{}'", routingKey);
}
private String createAndBindRequestQueue(String traceId, JobType jobType) {
Queue requestQueue = requestQueueProvider.getRequestQueue(jobType, traceId);
amqpAdmin.declareQueue(requestQueue);
String routingKey = requestQueue.getName();
Binding binding = BindingBuilder.bind(requestQueue)
.to(exchange)
.with(routingKey)
.and(Map.of("x-expires", requestQueueTtl.toMillis()));
amqpAdmin.declareBinding(binding);
return routingKey;
}
}When the process() method is invoked, the IC is sending a job request to the dynamically created and bound queue. The creation and binding happen in the createAndBindRequestQueue() method.
There's quite a lot going on in that class. Imagine writing an integration test that would cover all that logic!
There’s another challenge. Consider the createAndBindRequestQueue() method. If you mock all the methods used in it, namely declareQueue() and declareBinding(), will it really help you? Sure, you can verify if those methods were invoked, or try to return a value (if it’s possible), but it’s not actually the same as running the code live.
An approach using mocks might look like this:
@Test
void queueShouldBeDeclaredAndBoundDuringCreation() {
when(queue.getName()).thenReturn(QUEUE\_NAME);
when(exchange.getName()).thenReturn(EXCHANGE\_NAME);
step().process(context);
verify(amqpAdmin).declareQueue(queue);
ArgumentCaptor<Binding> bindingArgumentCaptor = ArgumentCaptor.forClass(Binding.class);
verify(amqpAdmin).declareBinding(bindingArgumentCaptor.capture());
Binding binding = bindingArgumentCaptor.getValue();
assertEquals(EXCHANGE\_NAME, binding.getExchange());
assertEquals(QUEUE\_NAME, binding.getRoutingKey());
assertEquals(QUEUE\_NAME, binding.getDestination());
}This might be considered a unit test, but it’s definitely not an integration test. What we need here is to verify whether the queue has been created for real and a message has been sent to it.
Here’s how to achieve that using Testcontainers.
@Slf4j
@SpringBootTest
@Testcontainers
class CommonJobRequestConsumerIT {
private static final int SPARK\_SERVER\_PORT = 4578;
@Container
private static final RabbitMQContainer container = new RabbitMQContainer(DockerImageName.parse("rabbitmq:3.8.14-management")) {
@Override
public void stop() {
log.info("Allow Spring Boot to finalize things (Failed to check/redeclare auto-delete queue(s).)");
}
};
@Autowired
private RabbitTemplate template;
@Value("${databricks.check-status-call-delay}")
private Duration statusCallDelay;
private static SparkService sparkServer;
@BeforeAll
static void before() {
sparkServer = SparkService.instance(SPARK\_SERVER\_PORT);
sparkServer.startWithDefaultRoutes();
}
@AfterAll
static void after() {
sparkServer.stop();
}
private <R extends SpecificRecordBase> void assertJobRequest(String expectedQueueName, Supplier<R> requestSupplier, JobSettingsProvider<R> jobSettingsProvider) throws IOException {
Message receivedRequest = template.receive(expectedQueueName);
assertNotNull(receivedRequest);
R serializedRequest = AvroSerialization.fromJson(requestSupplier.get(), receivedRequest.getBody());
log.info("Request received in '{}' '{}'", expectedQueueName, serializedRequest.toString());
RunSettings jobSettings = jobSettingsProvider.getJobSettings(serializedRequest);
assertEquals(JOB\_ID, jobSettings.getJobId());
assertEquals(TRACE\_ID, jobSettings.getTraceId());
}
@ParameterizedTest
@MethodSource
<R extends SpecificRecordBase> void jobRequestShouldBeSentToDedicatedQueue(String requestRoutingKey, R request, String expectedQueueName, Supplier<R> requestSupplier, JobSettingsProvider<R> jobSettingsProvider) throws InterruptedException, IOException {
template.convertAndSend(Amqp.EVENTS, requestRoutingKey, request, m -> {
m.getMessageProperties().setDeliveryTag(1);
return m;
});
// finish all steps
// + give rabbit some time to finish with dynamic queue creation
long timeout = statusCallDelay.getSeconds() + 1;
TimeUnit.SECONDS.sleep(timeout);
assertJobRequest(expectedQueueName, requestSupplier, jobSettingsProvider);
}
}
As you can see, the test is readable and really easy to follow, which is not always the case when you mock. We start (in the before() method) with some Spark related logic (more on that later), and then we send a message to the queue, starting the entire process. This is exactly how the system under test (IC) works. It’s listening to a particular queue and once the message is there, it picks it up and starts processing it. In some cases, we need to wait a bit, since otherwise a test will finish too early and assertions will fail.
I think that proves that there is a good reason why using Testcontainers in similar cases could be an excellent choice. In my opinion, there is no better way to be certain this code works as expected.
I’m sure there are many other examples where mocking is not a viable solution, and the only reasonable option is to be able to run those components live. This is where the Testcontainers library shows its power and simplicity. Give it a try next time you write an integration test!
Hero #2: The Spark framework
In the same component (IC) I’m also using the Spark framework to handle HTTP calls to an external service, in this case, Databricks API. Spark is lightweight and perfect for such use cases. Instead of mocking RestTemplate calls, we are using a real HTTP server!
Why is that so important? Well, if you look at how our test is organised, I think it will become apparent. As mentioned earlier, I’m using Testcontainers to make the test as real as possible. I do not want to mock anything. I want my REST calls to be real as well.
Let’s look at how Spark is being used in this test. While working with Spark in integration tests, I’m using a wrapper class called SparkService.
@Slf4j
public class SparkService {
private final Service sparkService;
private SparkService(Service service) {
this.sparkService = service;
}
static File loadJsonPayload(String payloadFileName) {
ClassLoader classLoader = SparkService.class.getClassLoader();
URL resource = classLoader.getResource(payloadFileName);
return new File(resource.getFile());
}
public static SparkService instance(int dbServerPort) {
return new SparkService(Service.ignite().port(dbServerPort));
}
public void startWithDefaultRoutes() {
DatabricksRoutes.JOB\_LIST.register(sparkService);
DatabricksRoutes.JOB\_RUN\_NOW.register(sparkService);
DatabricksRoutes.JOB\_RUNS\_GET.register(sparkService);
DatabricksRoutes.JOB\_RUNS\_DELETE.register(sparkService);
}
public void stop() {
service().stop();
}
public void awaitInitialization() {
service().awaitInitialization();
}
public Service service() {
return sparkService;
}
}
Notice the startWithDefaultRoutes() method. It contains several lines where particular endpoints (which I would like to stub) are defined. I’m using enum classes for those endpoints, and each of the enum keys implements the SparkRoute interface.
public interface SparkRoute {
HttpMethod httpMethod();
String path();
Route route();
default void register(Service sparkService) {
register(sparkService, route());
}
default void register(Service sparkService, Route route) {
switch (httpMethod()) {
case GET:
sparkService.get(path(), route);
break;
case POST:
sparkService.post(path(), route);
break;
}
}
}
Here is an example of the JOB_LIST enum from the DatabricksRoutes class.
public enum DatabricksRoutes implements SparkRoute {
JOB\_LIST {
@Override
public String path() {
return "/api/2.0/jobs/list";
}
@Override
public Route route() {
return JobController.handleJobList("json/spark/jobs\_list\_response.json");
}
@Override
public HttpMethod httpMethod() {
return HttpMethod.GET;
}
}
}
Ok, so how are all of these used in actual integration tests? In a simple scenario where no special logic for the stubbed endpoints is required, it could look like this.
private static SparkService sparkServer;
@BeforeAll
static void before() {
sparkServer = SparkService.instance(SPARK\_SERVER\_PORT);
sparkServer.startWithDefaultRoutes();
}
@AfterAll
static void after() {
sparkServer.stop();
}
@DynamicPropertySource
static void properties(DynamicPropertyRegistry registry) {
registry.add("databricks.url=", () -> "http://localhost:" + SPARK\_SERVER\_PORT);
registry.add("databricks.token.token-host=", () -> "http://localhost:" + SPARK\_SERVER\_PORT);
registry.add("spring.rabbitmq.host", container::getContainerIpAddress);
registry.add("spring.rabbitmq.port", () -> container.getMappedPort(5672));
log.info("RabbitMQ console available at: {}", container.getHttpUrl());
}
I have not mentioned this earlier but in the properties() method above, you can see how RabbitMQ can be configured with Testcontainers. This method is where all the properties in which we need to specify a URL are overridden, so we could use Spark as a handler for the original REST calls to those default services.
That was a simple Spark usage scenario within an integration test. For more sophisticated logic, we need a bit of a different approach.
What if we have a parameterised test, and we need each given endpoint to return a different response for every run? In the example above, all the endpoints were defined before the test started. However, we can configure particular endpoint handlers inside each test. This is where Spark can show its power of configuration and customisation in handling incoming requests.
For instance, consider this example:
sparkServer.registerGetRoute(JOB\_RUNS\_GET\_PATH, handleRunsGet(jobRunDataPath));
sparkServer.awaitInitialization();jobRunDataPath is one of the parameters in a parameterised test, so we can register a different request handler and return a custom response (a JSON file) for every test run.
Try it out!
To sum up, I believe that Testcontainers and the Spark framework will change your habits when writing integration tests.
By leveraging the power of containerisation, you can move your tests to the next level by making them more reliable and even easier to write. You will be able to verify your system under test in almost the same conditions as if it was running on production. Furthermore, your test can eventually become even more readable.
Give it a try and see how easy it is to write integration tests now!