POSTED ON 26 NOV 2020
READING TIME: 6 MINUTES
An approach to speeding up Jenkins parallel builds
Having successful test automation in a software project is always a challenge. The usual test automation constraints are related to execution time and proper resource management. More in-detail tests need to be executed:
- On demand
- Within the shortest time
- With the lowest resource cost
In this article, I’m going to demonstrate how to reduce the above limitations using optimised parallel build approach with Jenkins. The method presented here helped me to lower execution time from 12 hours down to a 2 hour average in a production software project.
Parallel Job Execution in Jenkins
In Jenkins, there are several ways to implement parallel job execution. One of the common approaches is the parent-child build model.
In this model - a parent (upstream) job is triggering child (downstream) jobs.
The solution should be flexible in terms of child resource allocation, i.e. amount of downstream jobs to be triggered simultaneously, so usually, the parent job decides (statically or dynamically) how many child jobs (N) should run in parallel.
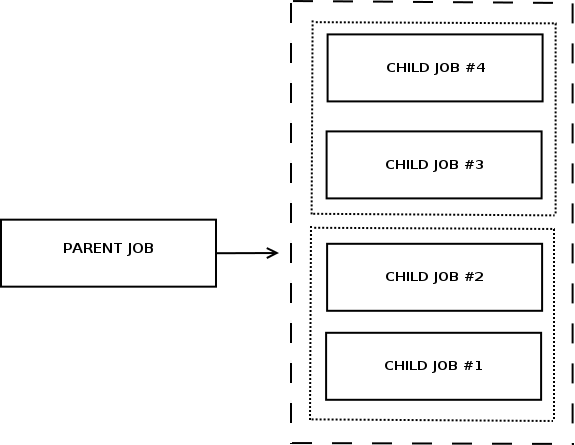
Parent Job optimisations
The parent job should help downstream jobs in their repeatable steps.
For example, a typical repeatable step is the preparation of the job workspace. It can be prepared, zipped in a parent job and copied in downstream jobs to speed-up their execution.
Next, a properly written parent job should aggregate the execution results of a child job, to store them for further investigations.
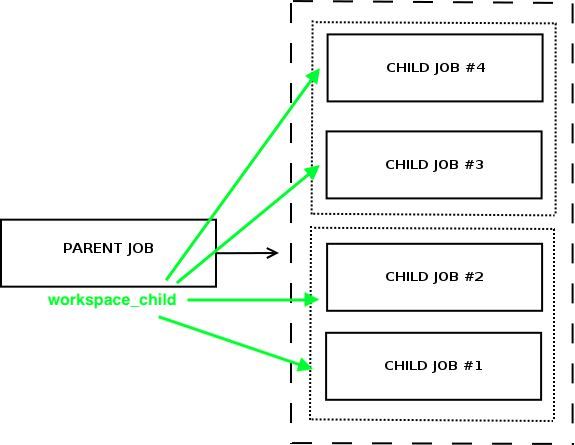
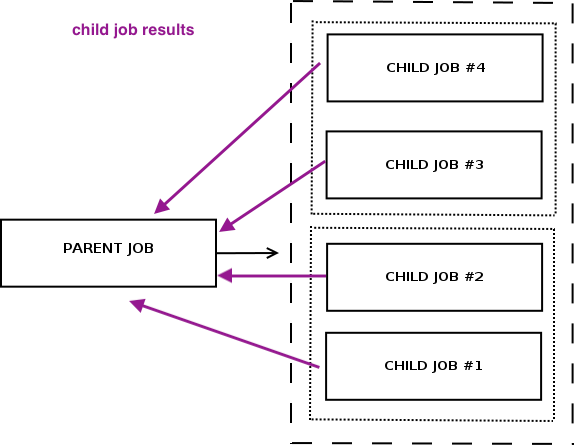
The benefits here are:
- Faster execution time when child job has a prepared workspace
- If the workspace preparation requires external API calls, this is done just once in the parent job
- A quick investigation of results associated with specific parent job run
Child job optimisations
A child job should be optimised towards
- Parallel execution
- Single execution mode
The same child job can be used by upstream jobs and by individual runs.
In particular - a properly written child job should store the results for further investigations, and pass them to include into a parent job results in case of parent call. The benefits here are:
- Reuse of child job for both single and parallel runs
- Lower maintenance cost, as there is no need to write a separate job for single and parallel runs
Sharing results of a parent-child
Copying the results of a specific child job run is a challenge in Jenkins, when concurrent child jobs are running in parallel.
To copy artifacts from the specific build of "downstream" according to: https://plugins.jenkins.io/copyartifact/
def built = build('downstream');
copyArtifacts(projectName: 'downstream', selector: specific("${built.number}"));In particular, for GUI parent jobs, it is possible to copy the results from a specific numbered child build. In the case of pipeline approach (Jenkinsfile), the solution seems to be possible via the external storage approach. This storage could be a git repository (free Bitbucket hosting) or better yet AWS S3 storage.
So, the child job drops the results to the storage, later they are downloaded by the parent at the final stage.
Further, only failed results should be downloaded back to the parent job from the whole result set, helping to avoid redundant data transfer and delusion. The user is usually interested in failed execution reports to investigate them at a first-glance. In case of further investigations, all results are stored externally but only failed ones are transferred back to Jenkins, which is cheaper.
The results may also have a retention policy, i.e. automated deletion on external storage after some days.
Parent-child - possible implementations table
Jenkins offers both ways of implementing the above solutions, using plugins with GUI and with Jenkinsfile pipelines.
| Parent job implementation | Child job implementation | Advantages | Disadvantages | External storage for child results | Execution time cost |
|---|---|---|---|---|---|
| GUI | GUI | Only GUI, no need for code skills on programming Jenkins job behaviour Does not require specialised library | Need to force static amount of threads to run and wait till they are finished The GUI job is hard to maintain on both levels: parent and child | Not necessary | 100% |
| GUI | Jenkinsfile | Does not require specialised library | Need to force static amount of threads to run and wait till they are finished
The GUI job is hard to maintain on parent level |
Not necessary | 100% |
| Jenkinsfile | GUI | Most optimised execution time | Hard initial step: Requires specialised library
Due to GUI harder to maintain than Jenkinsfile
The GUI job is hard to maintain on a child level Need external storage for child results to be picked up from parent |
Necessary | 75% |
| Jenkinsfile | Jenkinsfile | Most optimised execution time | Hard initial step: Requires specialised library Cheapest to maintain on both levels since Jenkinsfiles are used | Necessary | 75% |
Conclusion
As stated in the beginning, tests should be executed:
- On demand
- Within the shortest amount of time
- With the lowest resource cost
Based on our practical experience, the following optimisations in the parallel execution for parent-child model are recommended:
- It is way more efficient when both parent and child job use approach #4 from the above table, with a custom library for parallel operations, since:
- Maintenance cost is lowered for both parent and child jobs logic
- Execution time on such setup is reduced by 25% compared to GUI parent job
- There is an elastic way of handling resources for execution since the amount of child jobs can vary
- Performance is extended to the maximum if the child job reuses workspace prepared by a parent job
- It should be possible to execute child jobs in both single and parallel mode to lower down the maintenance cost of Jenkins build logic.
- Test execution results for parallel runs should be stored on storage outside of Jenkins:
- Only failed results are copied to a parent job
- An automated retention policy should be set towards stored test results
Finally - the above conclusions helped me to reduce execution time from 12 hours on-a-run on a single Jenkins executor down to 2 hours with the above recommendations using just three executors on a production software project.
My further areas of interest would focus on a dynamic allocation of Jenkins executors on the fly. However, the dynamic allocation problem depends not only on Jenkins setup but also on the specific software setup of a particular project. As an example the boundary condition would be a limitation of parallel processing depending on resources, e.g. on the amount of memory, CPU consumed during test execution on a software/device under test.